C++ Primer学习一
C++ Primer学习一
基础
main函数:程序入口。
复合类型 Compound Type:
- 引用 Reference
- 绑定一个本地变量 bind to a local variable,是一个已经存在值的引用(一个应用:节约传参过程中的拷贝,节省程序运行时间,当对象很大,并且拷贝很多的时候,使用引用的价值就体现出来了)
- 不能绑定一个字面常量literal / constant
- 指针 Pointer
- 指向想要改动数据的地址。
引用和指针一个很大的区别:引用要做初始化
const
- 和Reference一样,一定要做初始化
- not const -> const 是可以的, 反之不行
- 普通指针不能指向常量数据。
- top-level指针和low-level指针:从右往左读const,理解到底是顶层const还是底层const
含有可变形参的函数 initializer_list
注意参数是constant
1 | |
assert 断言调试用的,可以用#define NDEBUG屏蔽掉。
初始化列表提升性能,初始化列表和委托构造函数的结合,表明初始化列表的速度较快
1 | |
静态成员变量,只能类内定义,类外进行初始化,因为静态成员变量不属于任何一个对象。
连续容器
- vector和Array,99%的情况用vector。
- list:双向链表
- forward_list:单链表
- deque 双端队列,头尾插入很快,支持快速访问。
- string 字符串
emplace_back()比push_back()少了一步拷贝,直接进行构造,插入速度稍微快一些。
迭代器是左闭右开区间,end()指向最后一个元素的下一位
容器操作可能会使迭代器失效
添加元素,删除元素,扩容的时候可能会变化。
当我们使用迭代器的时候,尽可能减少迭代器使用范围。
多使用vec.begin()和vec.end(),及时的获取迭代器的开始和结束值,不要给他们赋值后使用。
1 | |
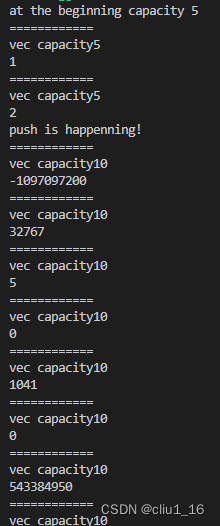
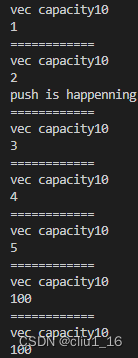
从上面的输出结果,和vector的扩容方式,以及迭代器指针失效的原因分析输出最后是两个100的情况:
vector中容量增长的方式,2^n方式去扩容,虽然是n倍,但是移动n个元素,平摊到每个元素上,时间复杂度依然是O(1)。
* 如果是vector< int > vec, 那么容器容量是0,1,2,4,8,16..增长
* 如果是vector< int > vec = { 1,2,3,4,5 },那么容器增长的步骤是5,10,20..按照初始大小两倍增长
* fun()中的代码: 在插入之前,vec的大小为5,push的时候,会先找到新的地址去扩容到10,然后push100,出现的情况就是,申请到了新的地址,但是用的老的迭代器,迭代器会不断地往后走,走到最新的地址空间去,会再次从1开始遍历,遍历到2的时候,会再push一个100,这就是为什么出现两个100的原因。
泛型算法
- 自己定义算法的比较器,注意比较的过程中怎么返回才能达到自己的效果:
1 | |
- lambda表达式:
C++可以调用的四种方法:
- function 函数 : void func();
- function pointer:bool (*pfunc) (int a); pfunc(1);
- class operator:类重载函数调用符
- lambda表达式
1 | |
1 | |
- 关联容器:
map set mulitiset multimap 有序,底层是红黑树,带Multi的可以有重复键值
unordered_set unordered_map 无序 底层为哈希表
注意map的用法 map[i]或者迭代器的 it->first 和 it->second
pair<int ,int> 很类似map中的节点
如果是自定义类的map,要告诉map怎么进行比较排序。
如果是自定义类的unordered_map,需要告诉unordered_map怎么hash1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class A{
public:
int a_;
A(int a):a_(a){}
};
bool WannaBigger(const A& a1, const A& a2){
return a1.a_ > a2.a_;
}
void func(){
map<A,int,decltype(WannaBigger)*> may_map(WannaBigger);
may_map.insert({A(1),1});
may_map.insert({A(2),2});
may_map.insert({A(3),3});
may_map.insert({A(4),4});
for(auto it= may_map.begin();it!=may_map.end();it++){
cout<<it->second<<endl;
}
}
动态内存
- 传统的new和delete申请释放内存的方法,如果new之后的内存没有delete释放,就会造成内存泄漏。
- delete掉之后,一般也会将指针置空,这个指针,也就变成了悬空指针。c++11之后,用nullptr,相比于NULL,nullptr是类型安全的,因为在某些情况下,编译器会把NULL和int搞混。
- 智能指针:shared_ptr,unique_ptr,weak_ptr。
- shared_ptr:共享指针,一般用make_shared< type >去初始化一个shared_ptr。shared_ptr的动态管理内存方式,当指向某个物体的shared_ptr个数降为0的时候,这个物体就会自动销毁,智能指针通过这种方式去管理内存,以避免内存泄漏,shared_ptr的具体方法叫引用计数,数一数有多少个指针指向某个物体。
- unique_ptr:一对一关系。C++14以后,可以用make_unique去新建一个独享指针。unique_ptr销毁的时候,其绑定的资源就会自动释放,不能普通拷贝,不能赋值给新的。只能用move去转移指针,但是没必要做吧。
1
2
3
4
5
6
7
8
9
10
11void some_func(){
Object* p = new Object();
p->foo(); // 如果这一步出错,下面的p就不会释放,还是会出问题,出现内存泄漏。
delete p;
}
void some_func2(){
unique_ptr<Object> up {make_unique<Object>()};
up->foo(); //即便抛出异常,资源最后也会释放。
}在默认情况下,unique_ptr用new和delete去申请和释放内存,但是可以自定义释放函数,值得注意的一点是,unique_ptr在自定义释放函数的,时候需要在模板函数里面,需要说明自定义释放函数的类型,因为unique_ptr的绑定释放函数是在编译期,减少了运行时绑定的损耗,shared_ptr的释放函数在运行时绑定,用户使用起来更简单,引用计数已经有运行时消耗了,再增加一点也无所谓
1 | |
- weak_ptr:没有权利控制对象生命周期,不会影响shared_ptr的计数值。